


Tout savoir sur le procès-verbal en copropriété
Le procès verbal de copropriété est un document important à archiver. Que doit-il comporter ? Combien de temps faut-il le conserver ? Tout ce que vous devez savoir dans cet article

Pourquoi détruire ses archives ?
Détruire ses archives est essentiel pour réduire les risques de fuite de données et pour alléger les finances de la copropriété.
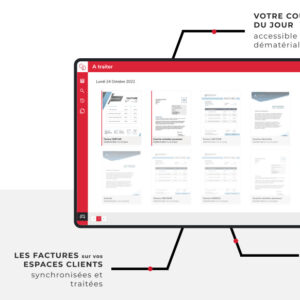
Qu’est-ce qu’une interface intuitive ?
Une interface intuitive vous permet de retrouver toutes les informations dont vous avez besoin en quelques clics !